
Künstliche Intelligenz
Intelligente Maschinen als Evolution der Immobilienbranche

Kaum ein Thema versetzt die Immobilienbranche mehr in Aufregung als „Künstliche Intelligenz“. Grund genug, die Begrifflichkeiten, Konzepte, Technologien und vor allem Potenziale etwas genauer unter die Lupe zu nehmen. Denn auch für Zukunftstechnologien gilt: Sie müssen sich bezahlt machen.
Begriffsklärung
Um auf einer gemeinsamen Basis zu diskutieren, sollten wir zunächst die beiden Begriffe Künstliche Intelligenz (KI) und Machine Learning voneinander abgrenzen. Künstliche Intelligenz (engl. Artificial Intelligence, AI) wird als Teilgebiet der Informatik verstanden. Das Konzept dahinter ist jedoch ein eher ideelles und vor allem nicht klar einzugrenzendes. Da „Intelligenz“ keiner eindeutigen Definition folgt, versteht man in der Regel darunter, die menschliche Intelligenz so gut wie möglich nachzubilden. Wie erfolgreich man damit ist, wird beispielsweise mit dem Turing-Test bestimmt – ein Versuchsaufbau, bei dem ein Mensch und die Maschine (Computer) in einem verdeckten Aufbau versuchen, eine Testperson davon zu überzeugen, dass sie denkende Menschen sind. Da man eher noch weit entfernt von einer „allgemeinen“ Intelligenz ist, fokussieren sich die Forschungsarbeiten zur Zeit auf eingegrenzte Wissensbereiche (Narrow AI).
In Abgrenzung dazu kann Machine Learning als Methode zur Erreichung von Künstlicher Intelligenz verstanden werden. Das Begriffspaar „Maschinelles Lernen“ beschreibt den Vorgang recht gut. Eine Maschine lernt. Das heißt, sie generiert Wissen aus Erfahrung. Dabei werden jedoch nicht nur Beispieldaten und Regeln auswendig gelernt (programmiert). Die Maschine soll vielmehr in die Lage versetzt werden, Muster und Gesetzmäßigkeiten selbständig zu erkennen, um im nächsten Schritt neue, unbekannte Daten zu beurteilen. Im Hintergrund arbeiten daran die sog. Algorithmen – systematische und logische Regeln, die die Basis der Berechnungen/Beurteilungen bilden.
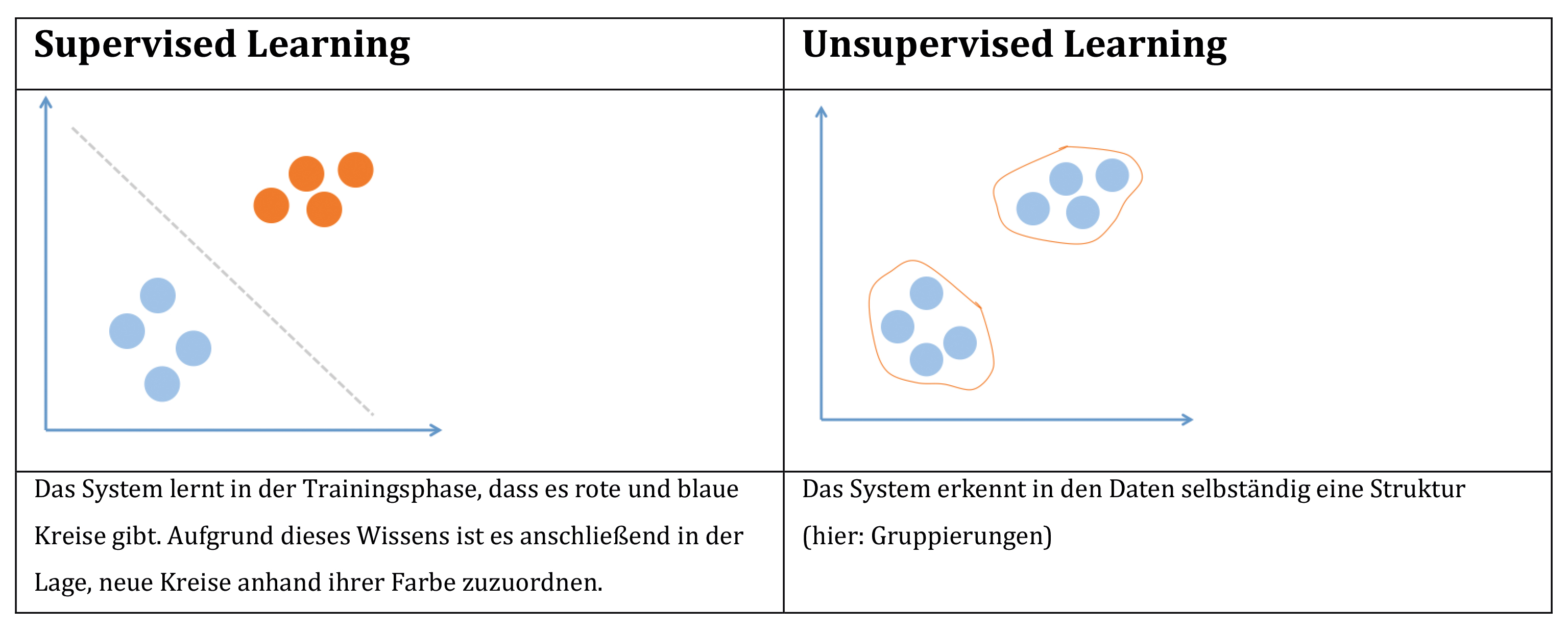
Supervised vs. unsupervised learning
Im Allgemeinen wird zwischen zwei Arten maschinellen Lernens unterschieden: überwachtes Lernen (Supervised Learning) und unüberwachtes Lernen (Unsupervised Learning). Während es bei Supervised Learning konkret darum geht, gelerntes Wissen auf neue Daten anzuwenden (zu generalisieren), ist das Ziel bei Unsupervised Learning, versteckte Strukturen in umfangreichen und/oder unübersichtlichen Daten zu entdecken. Beim Supervised Learning wird die Maschine mit bekannten Daten und Gesetzmäßigkeiten „gefüttert“, um ebenfalls bekannte, richtige Antworten zu finden. Klassische Anwendungsbeispiele sind die Handschrifterkennung („Sortiere neue Zeichen in die definierten Kategorien!“) oder Spam-Filter.
Beim Unsupervised Learning handelt es sich um das allgemeine Verstehen der vorliegenden Daten („Erkenne die Strukturen!“). Das System bildet selbst Kategorien und bietet Aussagen/Lösungen an. So werden in riesigen Datensätzen Strukturen erkannt und Gruppierungen gebildet, die dem menschlichen Auge aufgrund ihrer Komplexität eher verborgen geblieben wären.
Machine Learning im Dienst des Asset Managements
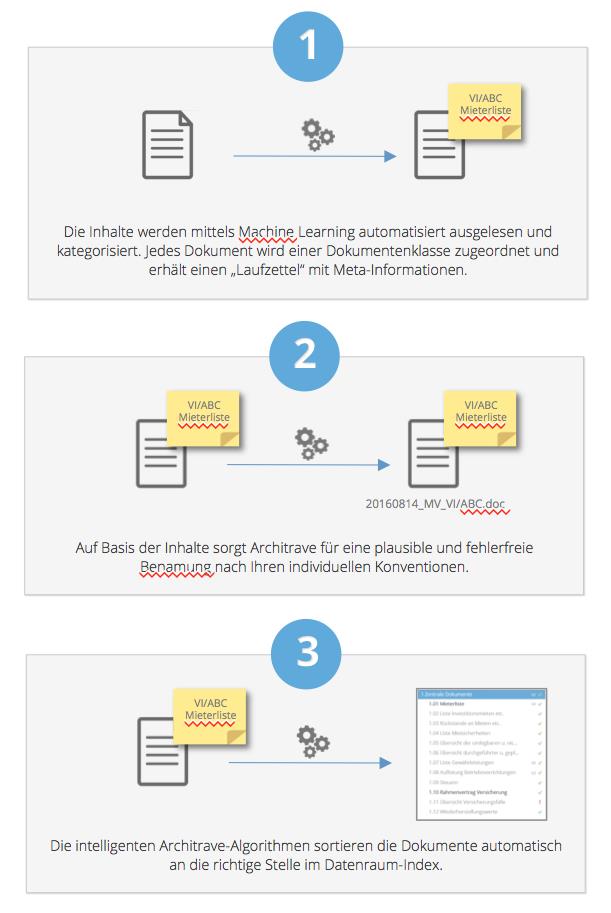
Jeder Asset Manager ist mit einer Unmenge von Dokumenten konfrontiert, die sein tägliches Arbeiten bestimmen. Häufig genug sind diese Dokumentenmassen noch chaotisch abgelegt und durchsetzt mit Duplikaten und irrelevanten Dokumenten. Machine Learning hilft schon heute, Dokumente zu erkennen und zu klassifizieren. Der Mietvertrag wird als Mietvertrag erkannt, das Wartungsprotokoll als Wartungsprotokoll. Mit Methoden des Supervised Learning wird bei Architrave mittlerweile eine hohe Trefferquote von erzielt.
Die erfolgreiche Klassifizierung generiert eine Menge weiterer Vorteile. Eine Maschine, die Dokumente automatisch erkennt und kategorisiert, kann diese Dokumente in weiteren automatischen Arbeitsschritten auch selbständig benennen, datieren, an die richtige Stelle in der Ablagestruktur sortieren und die Nutzer auf Lücken und Redundanzen hinweisen. Und das an sieben Tagen in der Woche rund um die Uhr – bei minimaler Fehlerquote.
Aus Dokumenten werden Daten
Weitaus komplexer als die Klassifizierung von Dokumenten gestaltet sich die Inhaltsextraktion. Natürlich ist es äußerst reizvoll, die Fülle von Daten aus Dokumenten auch digital vorliegen zu haben und auswerten zu können. Systeme zu entwickeln, die dies fehlerfrei und schnell ermöglichen, ist jedoch sehr aufwändig. Hauptgrund hierfür ist die weitaus komplexere und damit zeitintensive Aufbereitung der Trainingsdaten.
Bis die Auslesung und Auswertung weiterer Dokumentenarten technisch zuverlässig und wirtschaftlich abbildbar ist, ist noch einige Forschungsarbeit notwendig. Eine eigene Entwicklungsabteilung bei Architrave widmet sich aber bereits diesen Themen und treibt die Umsetzung intensiv voran.
Die Nutzungsrechte wurden The Property Post zur Verfügung gestellt von Architrave GmbH
Erstveröffentlichung: Architrave Blog, Januar 2017










